Read news on flash attention with our app.
Read more in the app
Forcing Flash Attention onto a TPU and Learning the Hard Way
AdapTive-LeArning Speculator System (ATLAS): Faster LLM inference
We reverse-engineered Flash Attention 4
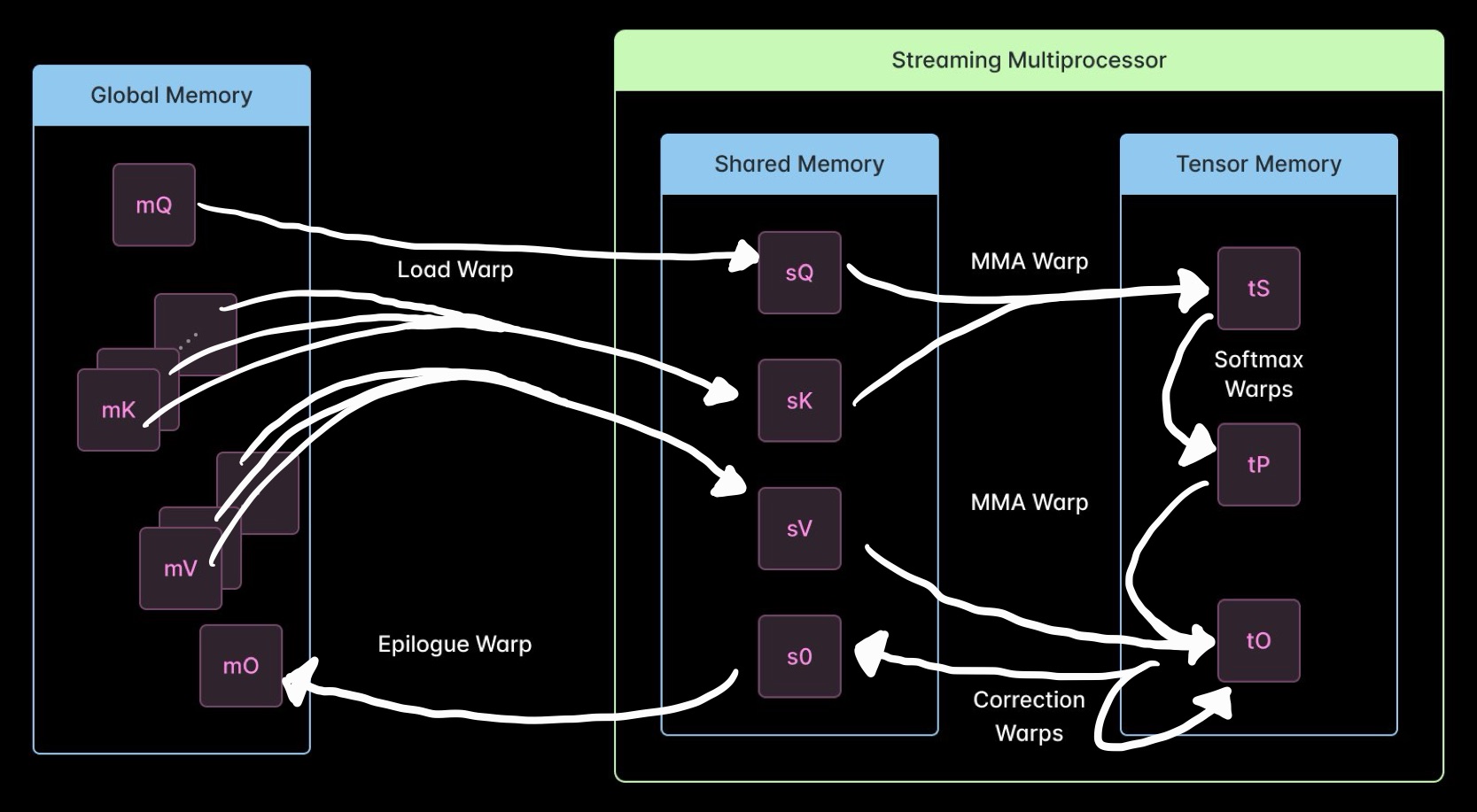
Writing Speed-of-Light Flash Attention for 5090 in CUDA C++
Implement Flash Attention Back End in SGLang – Basics and KV Cache