The first documented case of an end-to-end ransomware operation executed autonomously by an LLM has successfully performed extortion without a human operator.
LLM Usage in Debian: Three Proposals
Running a 28.9M parameter LLM on an $8 microcontroller
Canadian legislator reads out apparent LLM response in floor speech
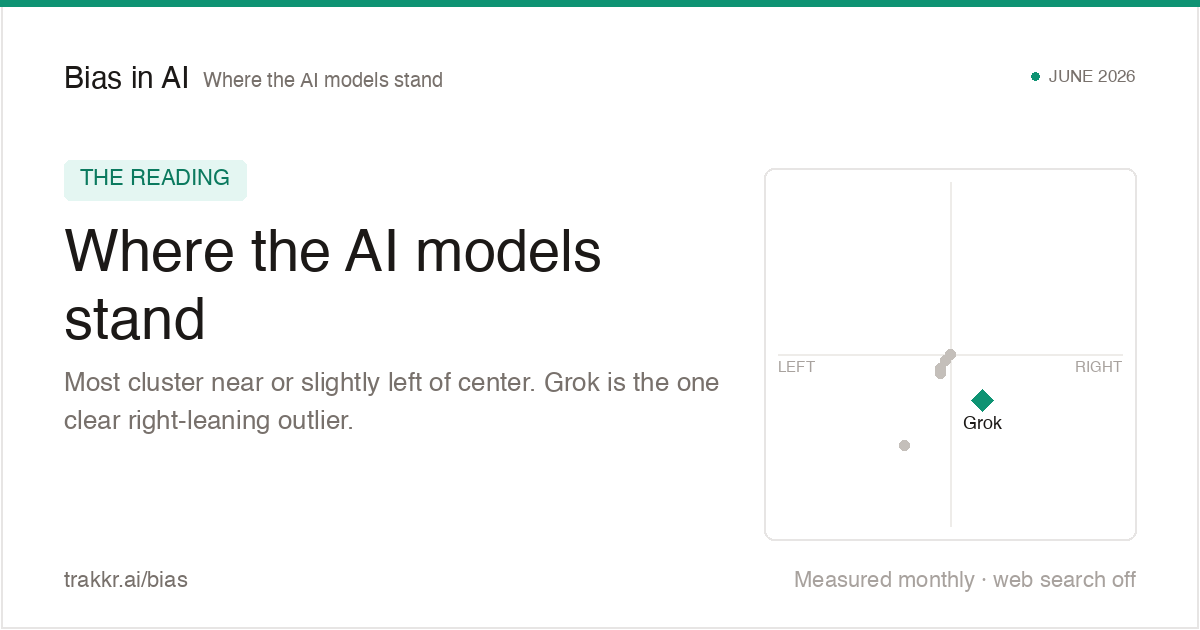
Writing fingerprint analysis of responses reveals Kimi's similarity to Claude
Six questions before you add an LLM
Show HN: We hid a backdoor in an LLM – $51,200 on finding it