Read news on MoE with our app.
Read more in the app
Granite 4.1: IBM's 8B Model Matching 32B MoE
Flash-MoE: Running a 397B Parameter Model on a Laptop
Trinity large: An open 400B sparse MoE model
Nvidia debuts Nemotron 3 with hybrid MoE and Mamba-Transformer to drive efficient agentic AI
Automating Algorithm Discovery: A Case Study in MoE Load Balancing
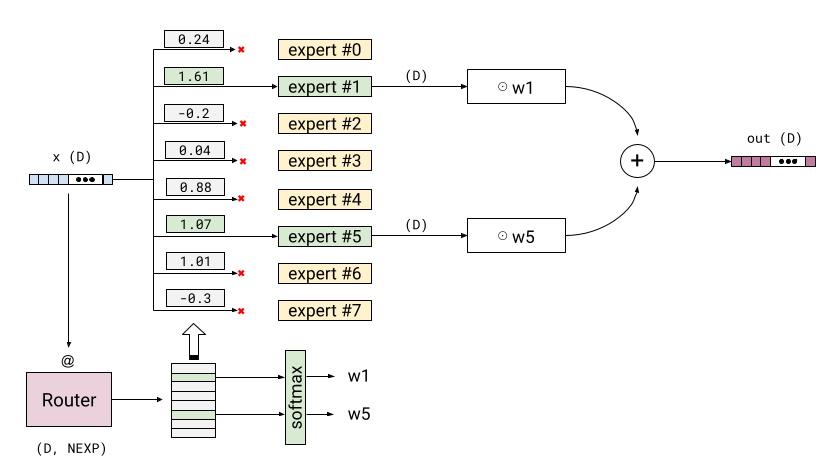
Sparsely-Gated Mixture of Experts (MoE)

.png)