Read news on time LLM Inference with our app.
Read more in the app
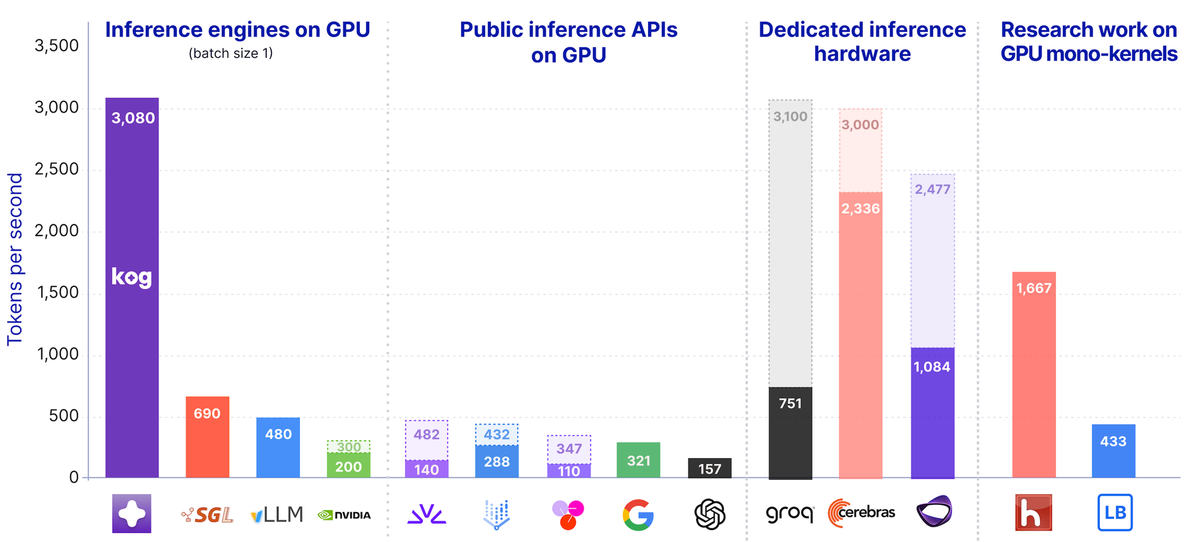
Real-time LLM Inference on Standard GPUs: 3k tokens/s per request