Get the latest tech news
None
Get the Android app
Read more on:
faster inference
IndexCache
context AI models
Related news:
Executing programs inside transformers with exponentially faster inference
Mixture-of-recursions delivers 2x faster inference—Here’s how to implement it
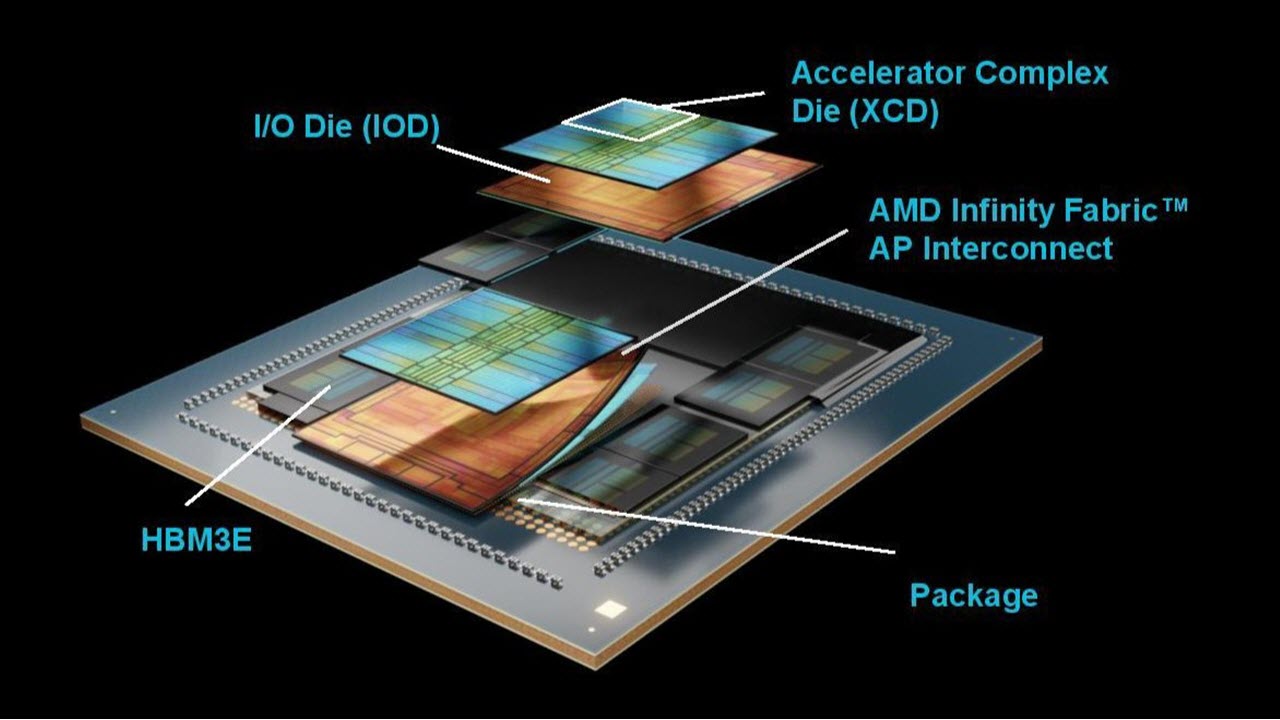
AMD announces MI350X and MI355X AI GPUs, claims up to 4X generational performance gain, 35X faster inference