Get the latest tech news
Diffusion models explained simply
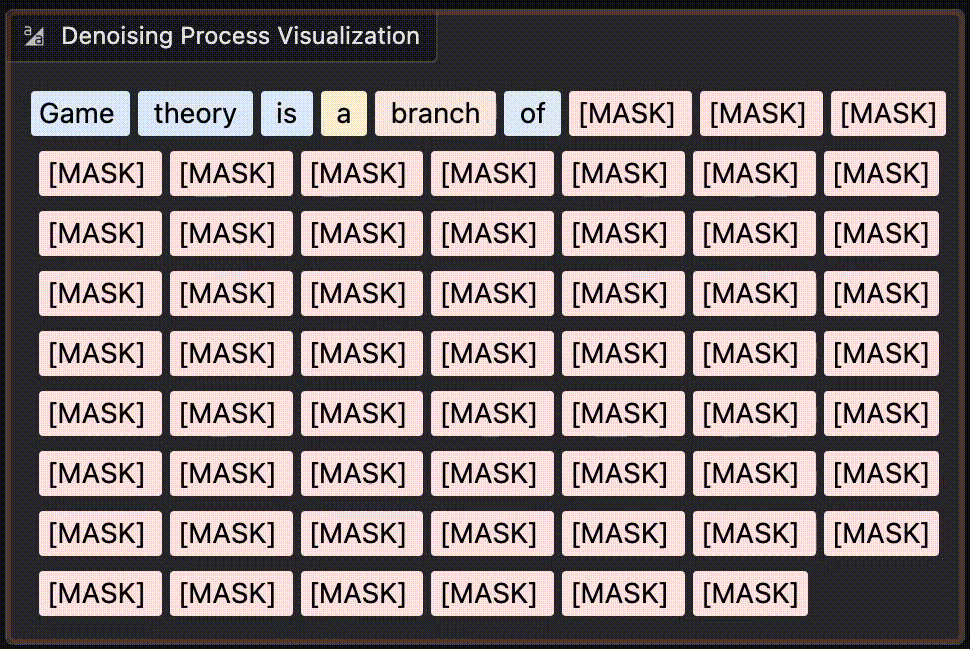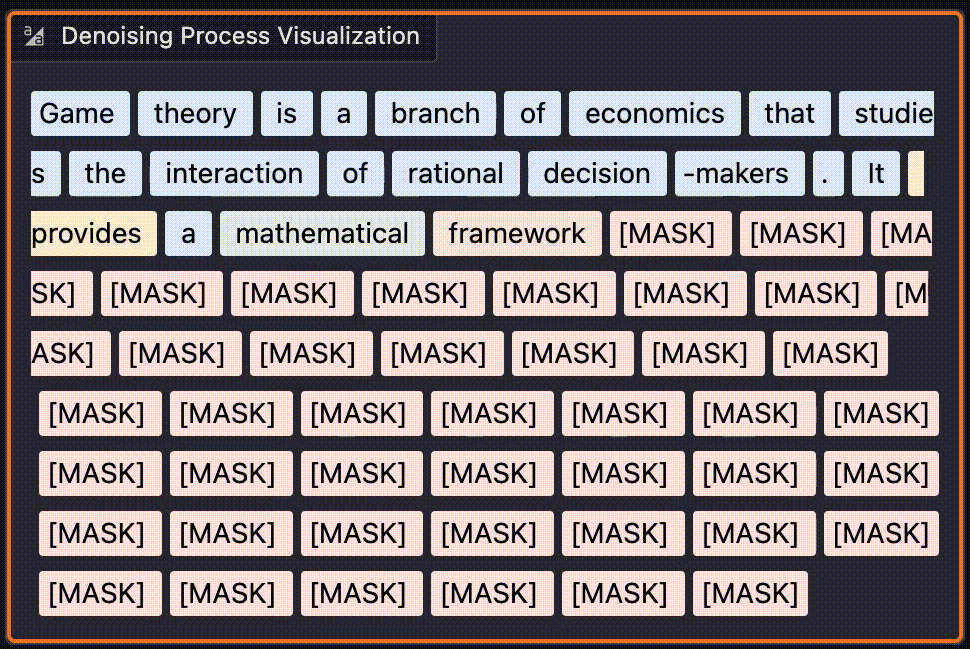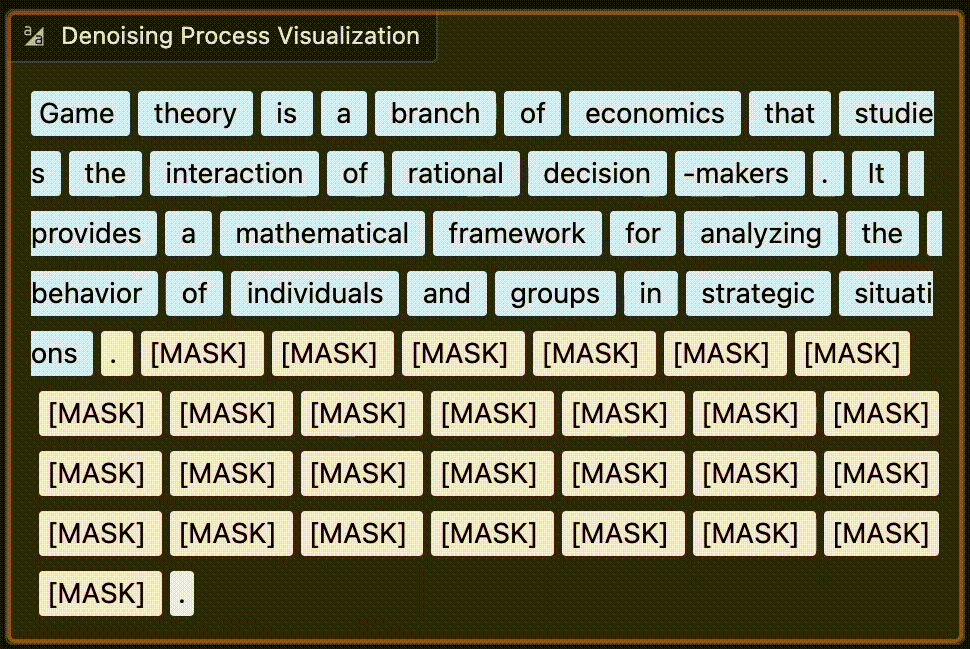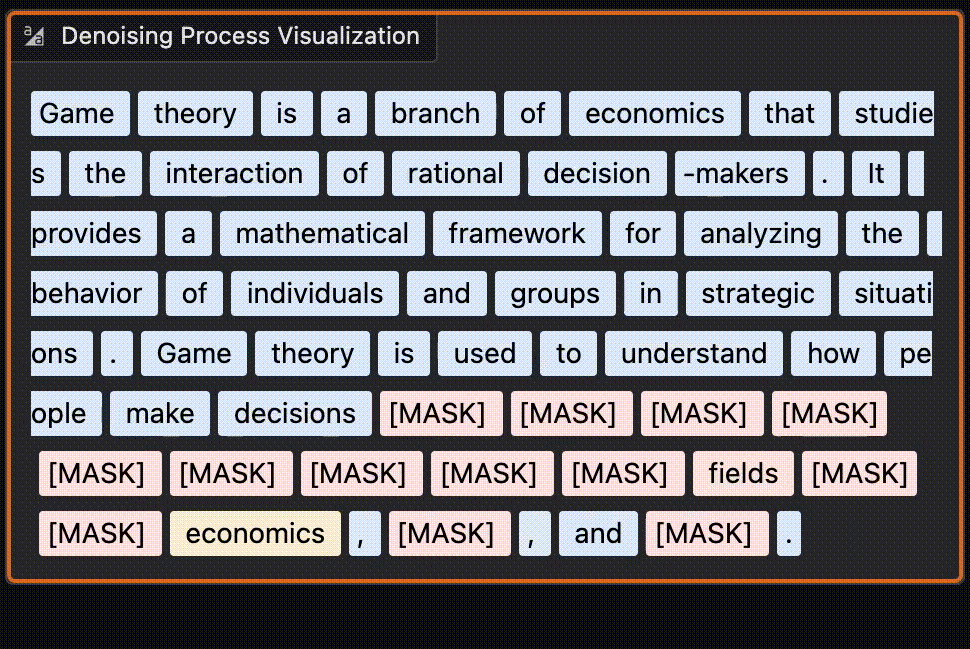
Transformer-based large language models are relatively easy to understand. You break language down into a finite set of “tokens” (words or sub-word components…
Despite some clever tricks (mainly about how the model processes the previous tokens in the sequence), the core mechanism is relatively simple. If you want fast inference at the cost of quality, you can just run the model for less time and end up with more noise in the final output. At inference time, you start with a big block of pure-noise embeddings (presumably just random numbers) then denoise until it becomes actual decodable text.
Or read this on Hacker News