Read news on faster inference with our app.
Read more in the app
Mixture-of-recursions delivers 2x faster inference—Here’s how to implement it
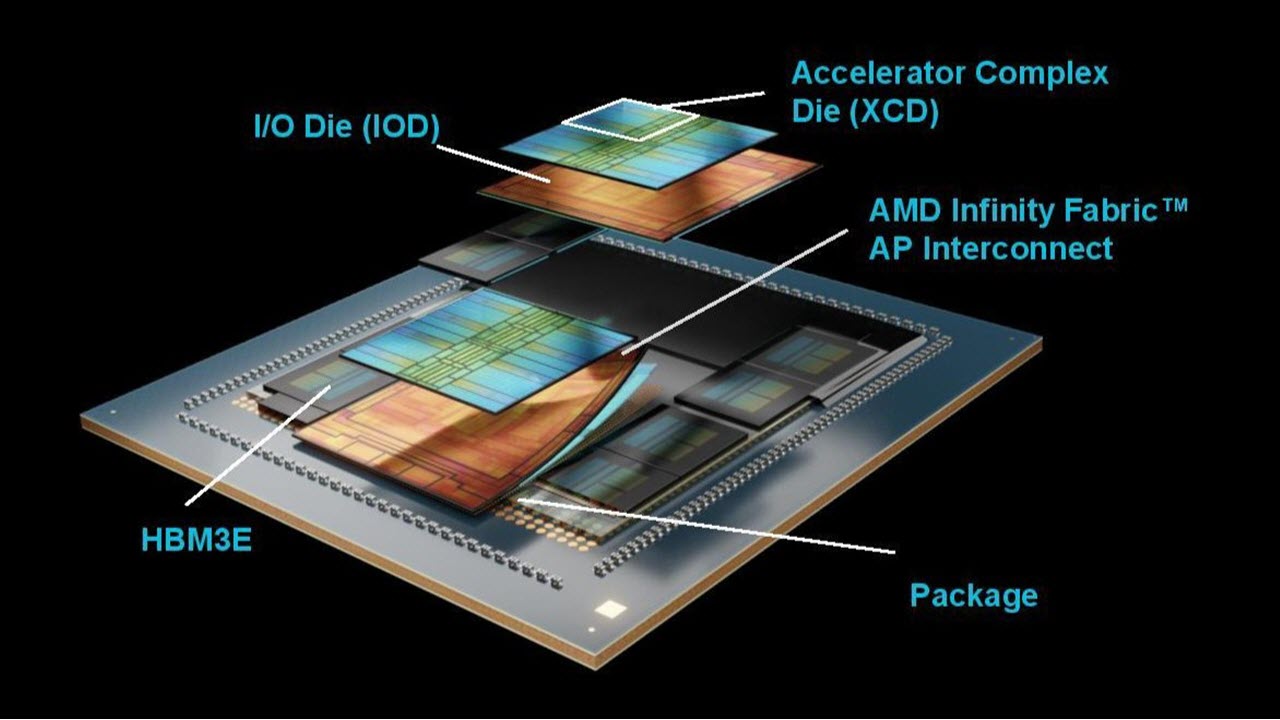
AMD announces MI350X and MI355X AI GPUs, claims up to 4X generational performance gain, 35X faster inference
Together AI promises faster inference and lower costs with enterprise AI platform for private cloud
26× Faster Inference with Layer-Condensed KV Cache for Large Language Models