NVIDIA DGX Spark In-Depth Review: A New Standard for Local AI Inference
Famed gamer creates working 5 million parameter ChatGPT AI model in Minecraft, made with 439 million blocks — AI trained to hold conversations, working model runs inference in the game
How Neural Super Sampling Works: Architecture, Training, and Inference
Nvidia’s $46.7B Q2 proves the platform, but its next fight is ASIC economics on inference
Are OpenAI and Anthropic losing money on inference?
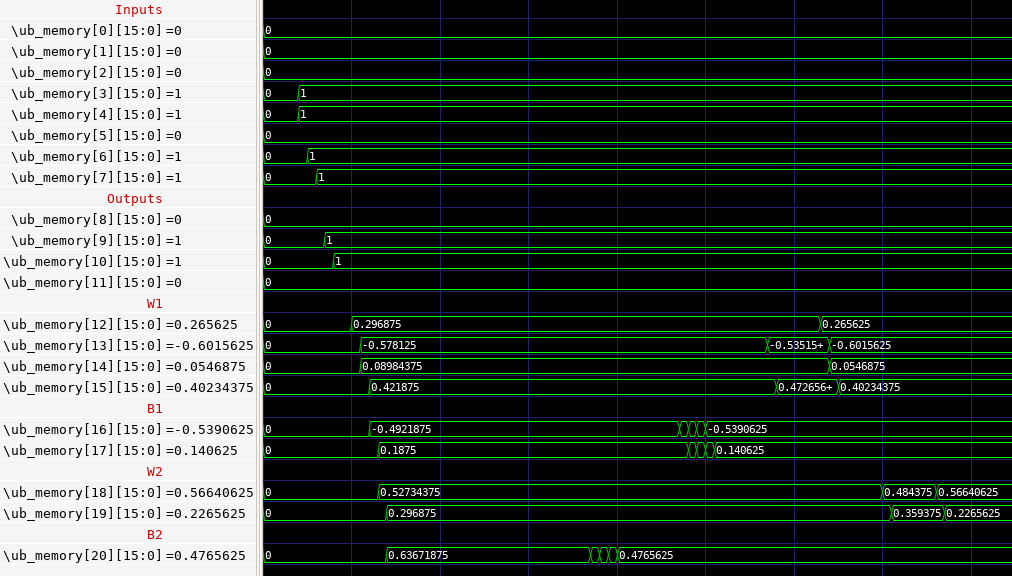
Show HN: I built a toy TPU that can do inference and training on the XOR problem
Nonogram: Complexity of Inference and Phase Transition Behavior
Cracking AI’s storage bottleneck and supercharging inference at the edge