Read news on LLM Inference with our app.
Read more in the app
Defeating Nondeterminism in LLM Inference
PyTorch 2.8 Released With Better Intel CPU Performance For LLM Inference
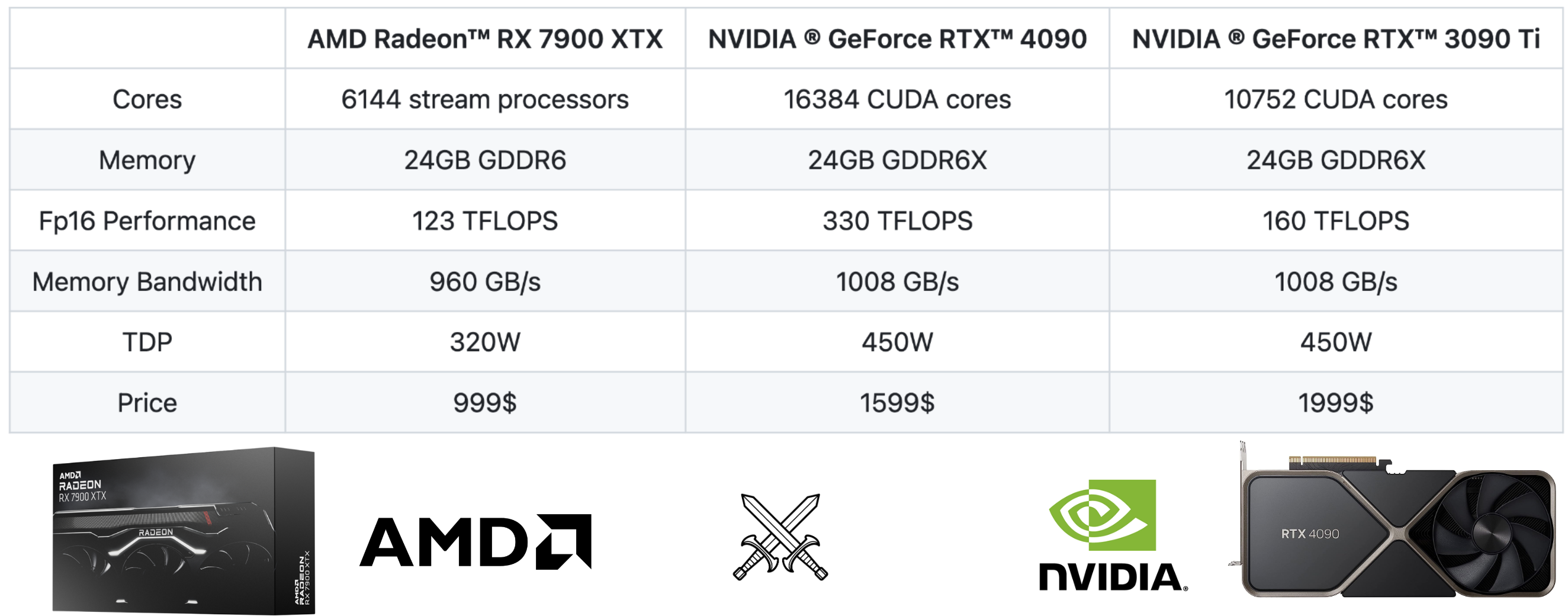
Making AMD GPUs competitive for LLM inference (2023)
How We Optimize LLM Inference for AI Coding Assistant
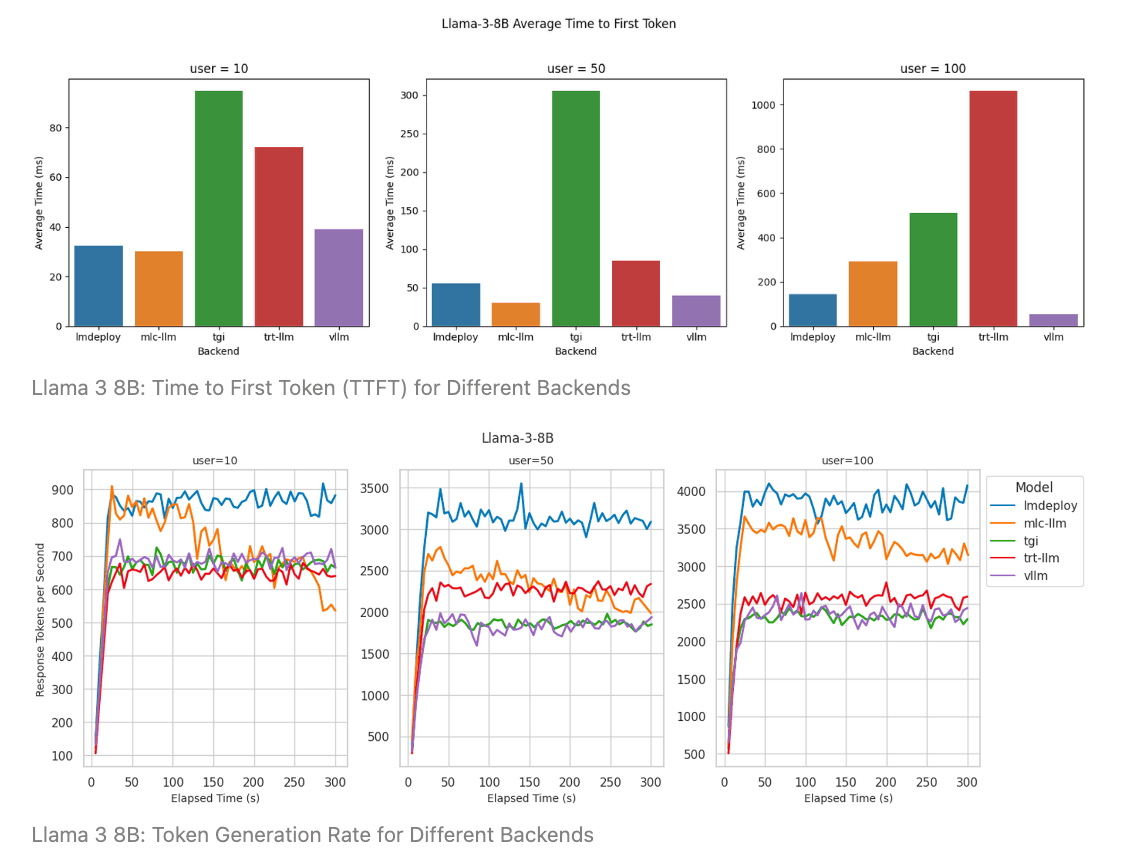
Benchmarking LLM Inference Back Ends: VLLM, LMDeploy, MLC-LLM, TensorRT-LLM, TGI
AMD's MI300X Outperforms Nvidia's H100 for LLM Inference
How attention offloading reduces the costs of LLM inference at scale
Show HN: Speeding up LLM inference 2x times (possibly)
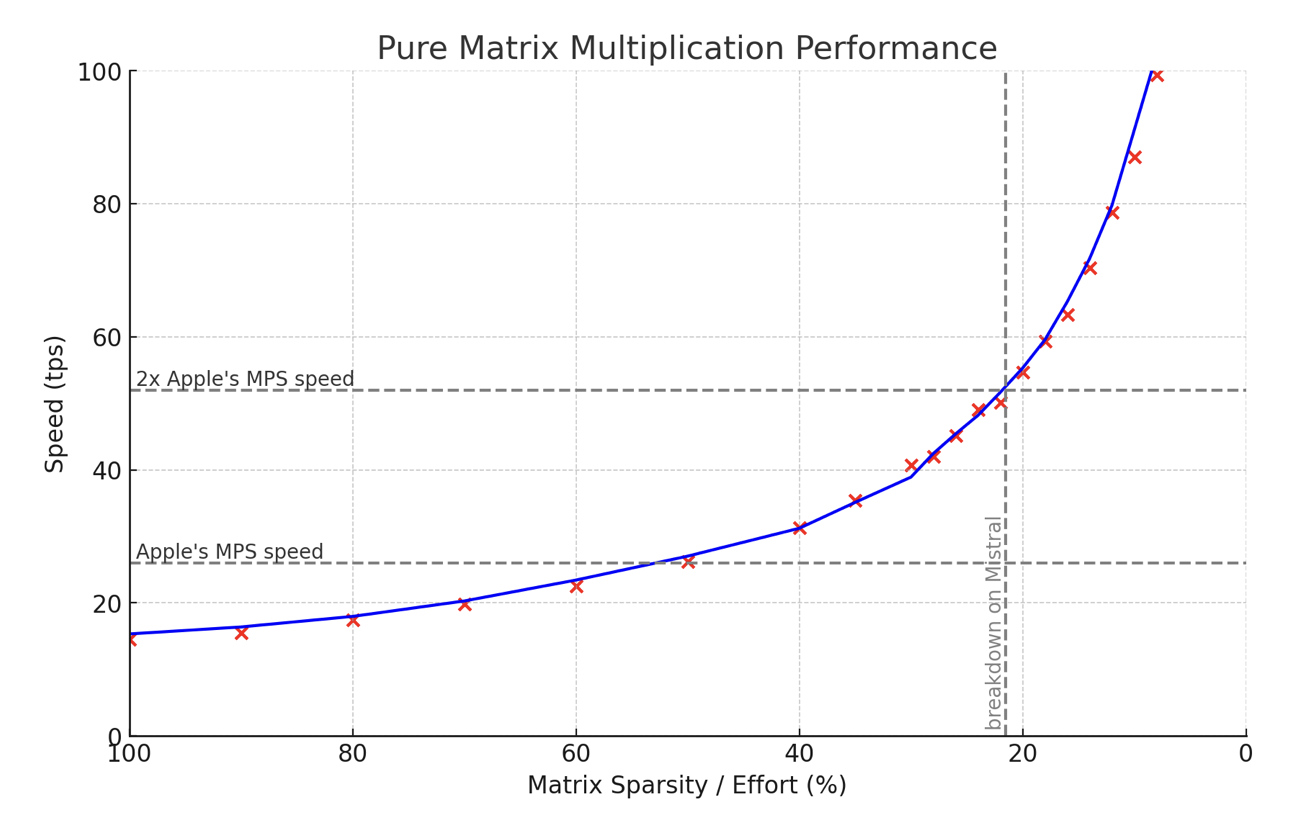
Effort – a possibly new algorithm for LLM Inference

.png)