Read news on tokens with our app.
Read more in the app
Claude vs. Gemini: Testing on 1M Tokens of Context
Apple taught an LLM to predict tokens up to 5x faster in math and coding tasks
Running GPT-OSS-120B at 500 tokens per second on Nvidia GPUs
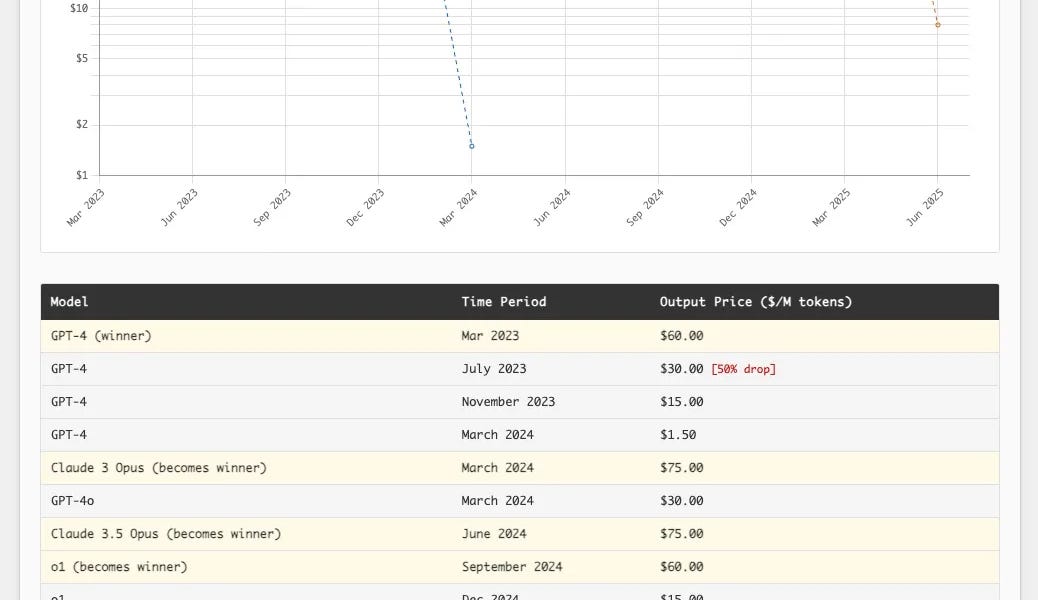
Tokens are getting more expensive
Cerebras launches Qwen3-235B, achieving 1.5k tokens per second
From tokens to thoughts: How LLMs and humans trade compression for meaning
Not all tokens are meant to be forgotten
Thailand to Issue $150 Milllion in Government Investment Tokens
Byte latent transformer: Patches scale better than tokens (2024)
Meta unleashes Llama API running 18x faster than OpenAI: Cerebras partnership delivers 2,600 tokens per second
When AI reasoning goes wrong: Microsoft Research shows more tokens can mean more problems
OpenAI’s new GPT-4.1 models can process a million tokens and solve coding problems better than ever
DeepSeek-V3 Now Runs At 20 Tokens Per Second On Mac Studio
DeepSeek-V3 now runs at 20 tokens per second on Mac Studio, and that’s a nightmare for OpenAI
Locks, leases, fencing tokens, FizzBee
Qwen2.5-1M: Deploy your own Qwen with context length up to 1M tokens
Malicious PyPi package steals Discord auth tokens from devs
Meta’s new BLT architecture replaces tokens to make LLMs more efficient and versatile
Byte Latent Transformer: Patches Scale Better Than Tokens
Hyrumtoken: A Go package to encrypt pagination tokens