Get the latest tech news
LLM-D: Kubernetes-Native Distributed Inference at Scale
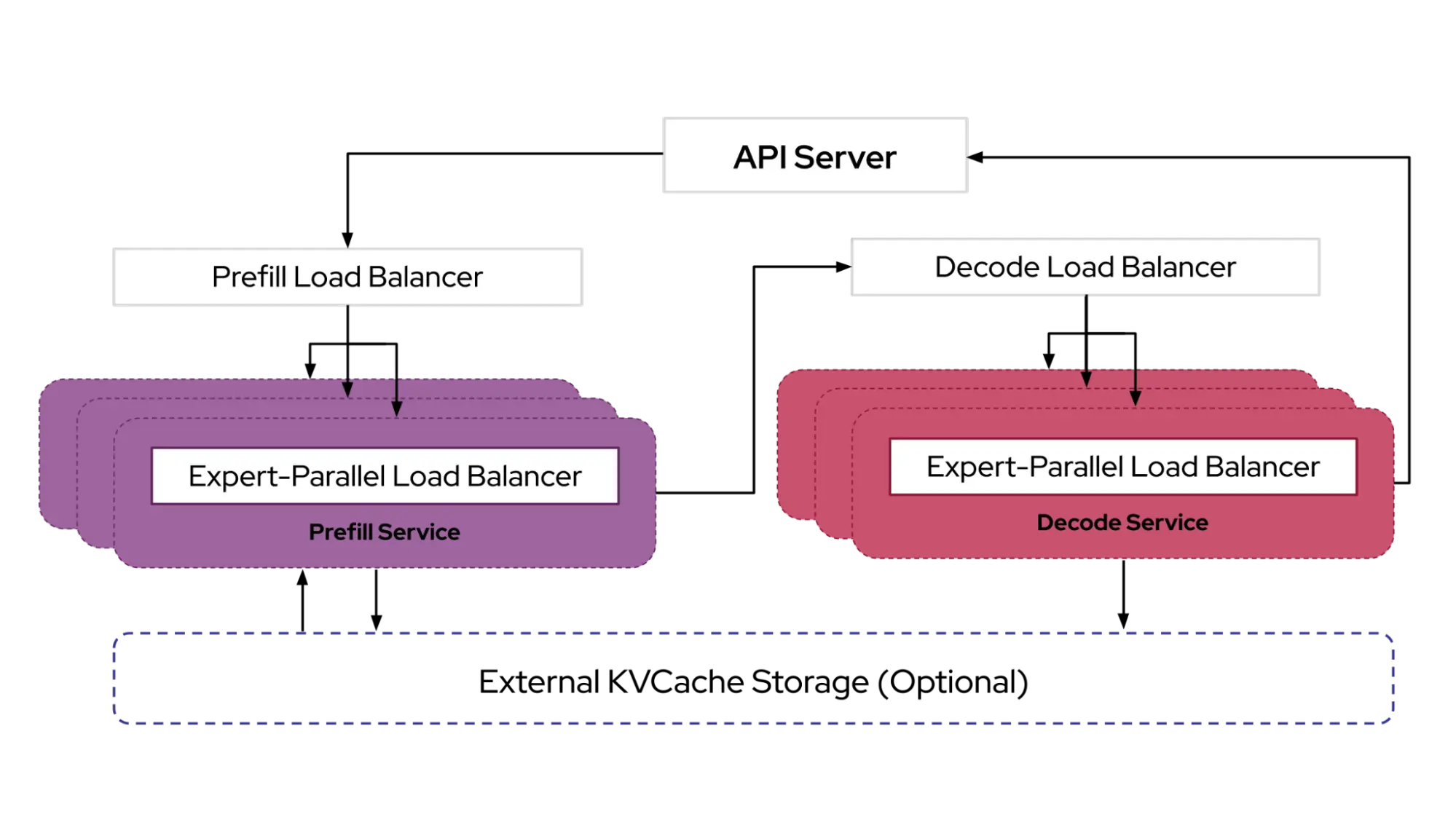
llm-d is a Kubernetes-native high-performance distributed LLM inference framework - llm-d/llm-d
llm-d adopts a layered architecture on top of industry-standard open technologies: vLLM, Kubernetes, and Inference Gateway. Leveraging operational telemetry, the Inference Scheduler implements the filtering and scoring algorithms to make decisions with P/D-, KV-cache-, SLA-, and load-awareness. Variant Autoscaling over Hardware, Workload, and Traffic(🚧): We plan to implement a traffic- and hardware-aware autoscaler that (a) measures the capacity of each model server instance, (b) derive a load function that takes into account different request shapes and QoS, and (c) assesses recent traffic mix (QPS, QoS, and shapes) to calculate the optimal mix of instances to handle prefill, decode, and latency-tolerant requests, enabling use of HPA for SLO-level efficiency.
Or read this on Hacker News