Get the latest tech news
The bitter lesson is coming for tokenization
Highlights the desire to replace tokenization with a general method that better leverages compute and data. We'll see tokenization's fragility and review the Byte Latent Transformer arch.
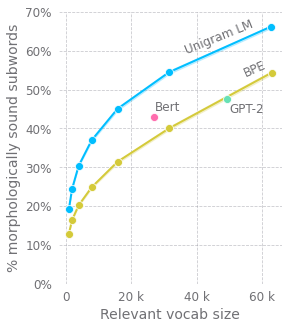
Ideally, the vocabulary of tokens is perfectly constructed for the task at hand such that it obtains the optimal trade off of byte compression to reduce the transformer's FLOPS while maintaining enough of a granular representation to achieve the lowest possible loss. They showed that pure byte modelling, even when trained on 4x less data, had comparable or better performance to its SentencePiece counter part on a subset of benchmarks under 1B parameters (namely robustness to noise, word-level tasks like transliteration, morphological inflection, graphene-to-phoneme). On this point, I'd expect to see the reliance on flushing context for resolving "entropy drift" to be addressed with a more robust solution or its need completely negated as the Patcher LLM gets integrated or trained jointly with the BLT.
Or read this on Hacker News